







Just (Docu)Sign Here!
In our continuing series of you asked for it; you got it, we are pleased to announce that the DocuSign integration is now included in…

Customer Spotlight: Legal Media Inc (LMI)
Meet Legal Media When we ask you to imagine a live event, we’re guessing that most of you easily conjure up images of concerts, sporting…

Getting Started with Flex + Zapier: What can you do?
You know how we do things around here. Because we are by, of, and for the events industry, we want to make sure that we’re…
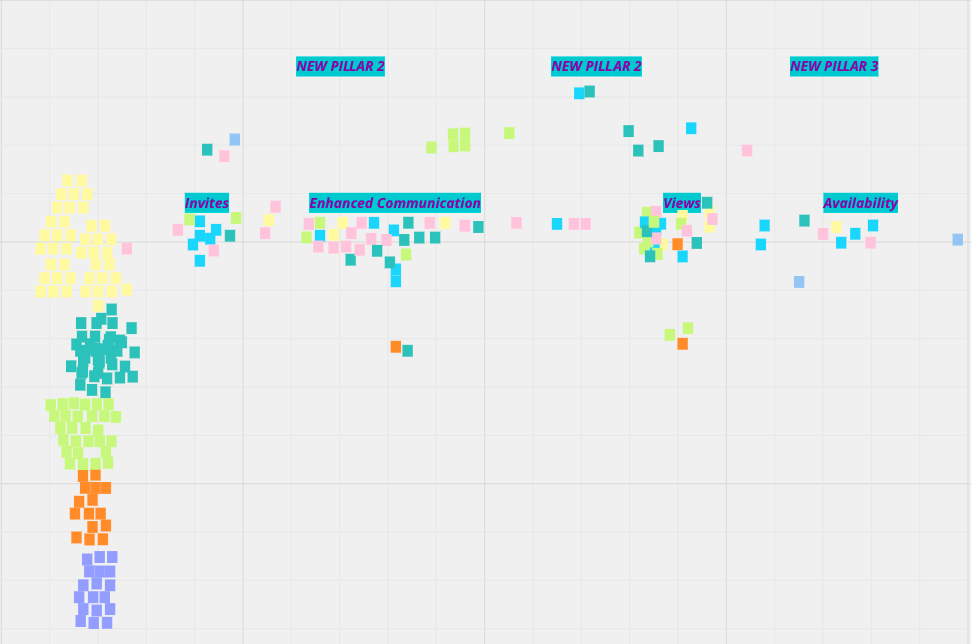
Flex StaffingPlus: The Product Owner’s View
Flex StaffingPlus As the only platform built from the ground up for the live events industry, Flex is in a unique position to feel the…
Announcing our most expansive in-platform functionality for event staffing management: Flex StaffingPlus
Flex StaffingPlus is a seamless, integrated solution that creates a better experience for Flex customers and their crews. SALT LAKE CITY, UT, – October 11,…

How Can the Most Flexible Platform Become Even More Flexible?
As the first-ever asset and inventory management solution built from the ground up for the events industry, we are proud of the fact that Flex is repeatedly…

Support Summit Recap: Hello from Houston! Clear Vision, Full Stomach, Can’t Lose.
Last week, CEO Chris Stein traveled to Houston, Texas, to meet with our Support Team. The purpose of the meeting was to connect, learn, and…

Chromebook Tracking Software: Helping School Districts With Asset Management
Getting back to school was challenging enough without adding the pandemic into the mix. Even before the pandemic, tracking a school’s assets was a…

Church Asset Tracking: Benefits & Best Practices to Consider
A church should be a safe haven, and safe havens require order and structure. Visitors to your church are eager to relax, meet like-minded people,…